DDD, Hexagonal, Onion, Clean, CQRS, ... 모두 종합한 방법
[번역] DDD, Hexagonal, Onion, Clean, CQRS, ... How I put it all together
ddd, hexagonal, onion, cqrs, translation
이 포스트는 소프트웨어 아키텍처에 관한 시리즈인 소프트웨어 아키텍처 연대기(The Software Architecture Chronicles)의 일부입니다. 해당 포스트들에서 저는 소프트웨어 아키텍처에 대해 배운 내용과 그것을 제가 어떻게 생각하며, 배운 지식을 실제로 어떻게 사용하는지에 대해 글을 씁니다. 이 포스트의 내용은 이 시리즈의 이전 포스트들을 읽으면 더 쉽게 이해할 수 있을 것입니다.
대학을 졸업한 후 저는 고등학교 교사로 일하다가, 몇 년 전 이 일을 그만두고 정식으로 소프트웨어 개발자가 되기로 결심했습니다.
그때부터 저는 항상 “잃어버린 시간”을 되찾아야 한다는 생각에, 가능한 한 빠르고 많은 것을 배워야 한다고 느꼈습니다. 그래서 특히 소프트웨어 디자인과 아키텍처 분야에 빠져들어 실험하고 읽고 쓰는 일에 중독되었습니다. 제가 이 포스트를 쓰는 이유도 바로 그렇게 배우는 과정에 도움을 주기 때문입니다.
지난 포스트들에서 제가 배운 많은 개념과 원칙들, 그리고 그것들에 대한 제 생각을 다뤘습니다. 하지만 저는 이 모든 것들이 하나의 큰 퍼즐을 이루는 조각들에 불과하다고 봅니다.
오늘 포스트는 제가 이 퍼즐 조각들을 어떻게 맞추는지에 관한 것입니다. 그리고 여기에 이름을 붙여야 할 것 같아서 저는 이를 명시적 아키텍처(Explicit Architecture) 라 부르기로 했습니다. 또한 여기서 소개할 개념들은 이미 실제 환경에서 “전투 시험”을 통과했으며, 높은 요구사항을 가진 프로덕션 코드에서도 성공적으로 사용되고 있습니다. 한 가지는 전 세계 수천 개의 웹 상점을 운영하는 SaaS 전자상거래 플랫폼이며, 다른 하나는 두 국가에서 운영되고 월 2천만 건 이상의 메시지를 처리하는 메시지 버스를 사용하는 마켓플레이스 플랫폼입니다.
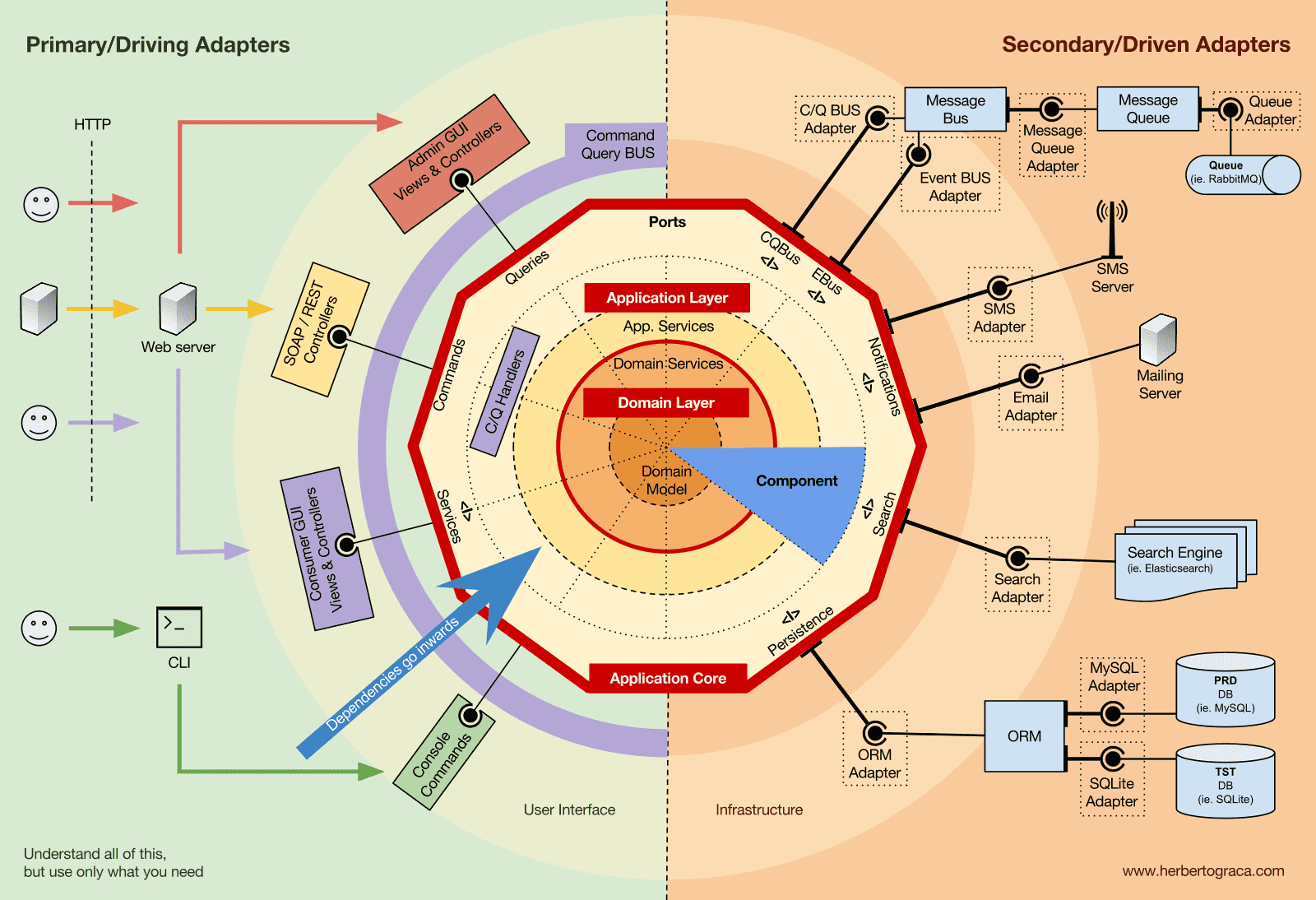
시스템의 기초 블록
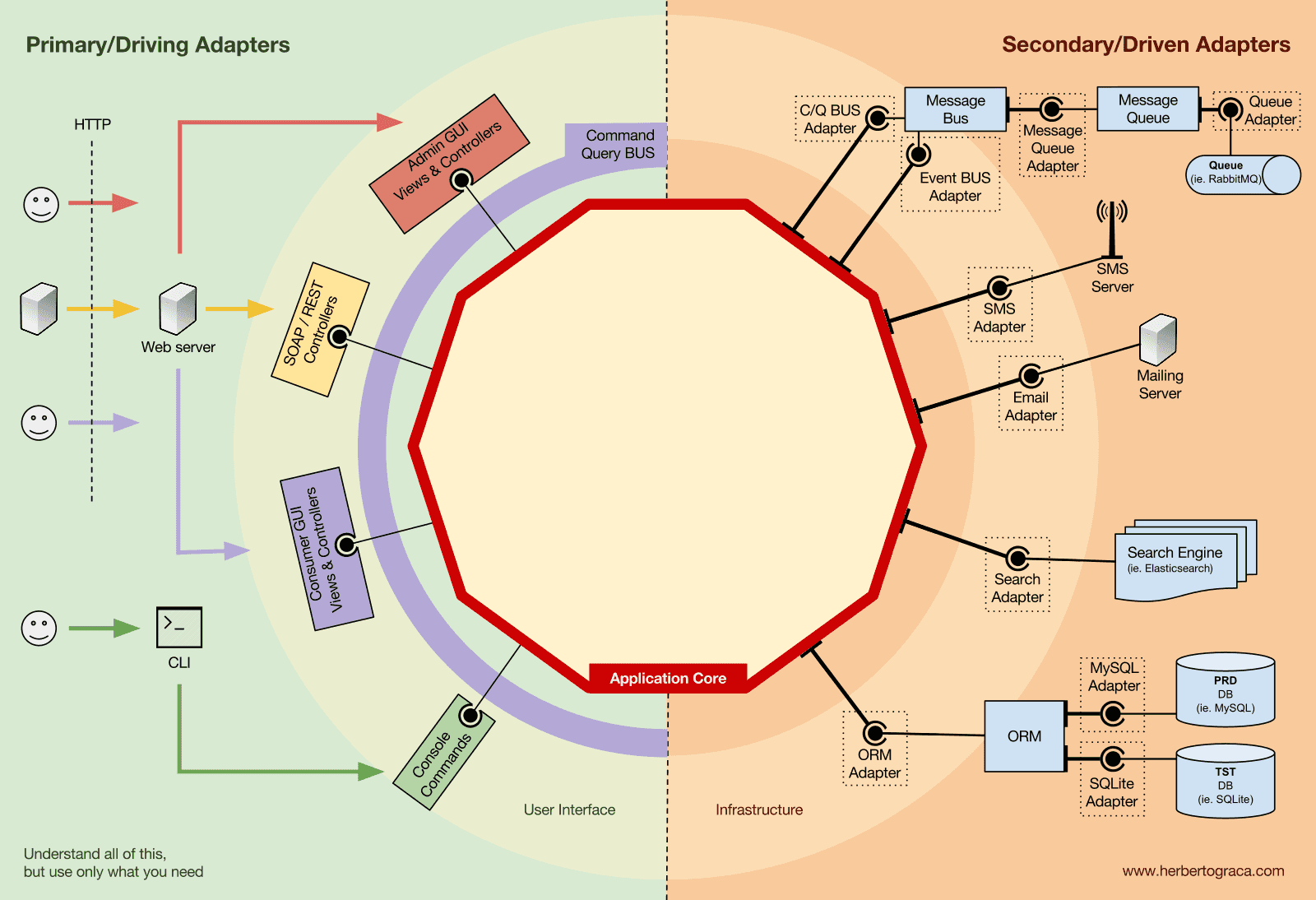
먼저 EBI(Entity-Boundary-Interactor)와 포트 & 어댑터(Ports & Adapters) 아키텍처부터 떠올려 봅시다. 두 가지 모두 애플리케이션 내부 코드와 외부 코드, 그리고 이 둘을 연결하는 코드를 명확하게 구분합니다.
특히 포트 & 어댑터 아키텍처는 시스템에서 세 가지 기본적인 코드 블록을 명시적으로 정의합니다.
- 사용자 인터페이스(User Interface) 어떤 형태의 사용자 인터페이스든 작동 가능하게 하는 코드입니다.
- 시스템 비즈니스 로직, 즉 애플리케이션 코어(Application Core) 사용자 인터페이스가 실제로 일을 수행하기 위해 호출하는 핵심 코드입니다.
- 인프라스트럭처(Infrastructure) 코드 애플리케이션 코어를 데이터베이스나 검색 엔진, 서드파티 API와 같은 도구들과 연결하는 코드입니다.
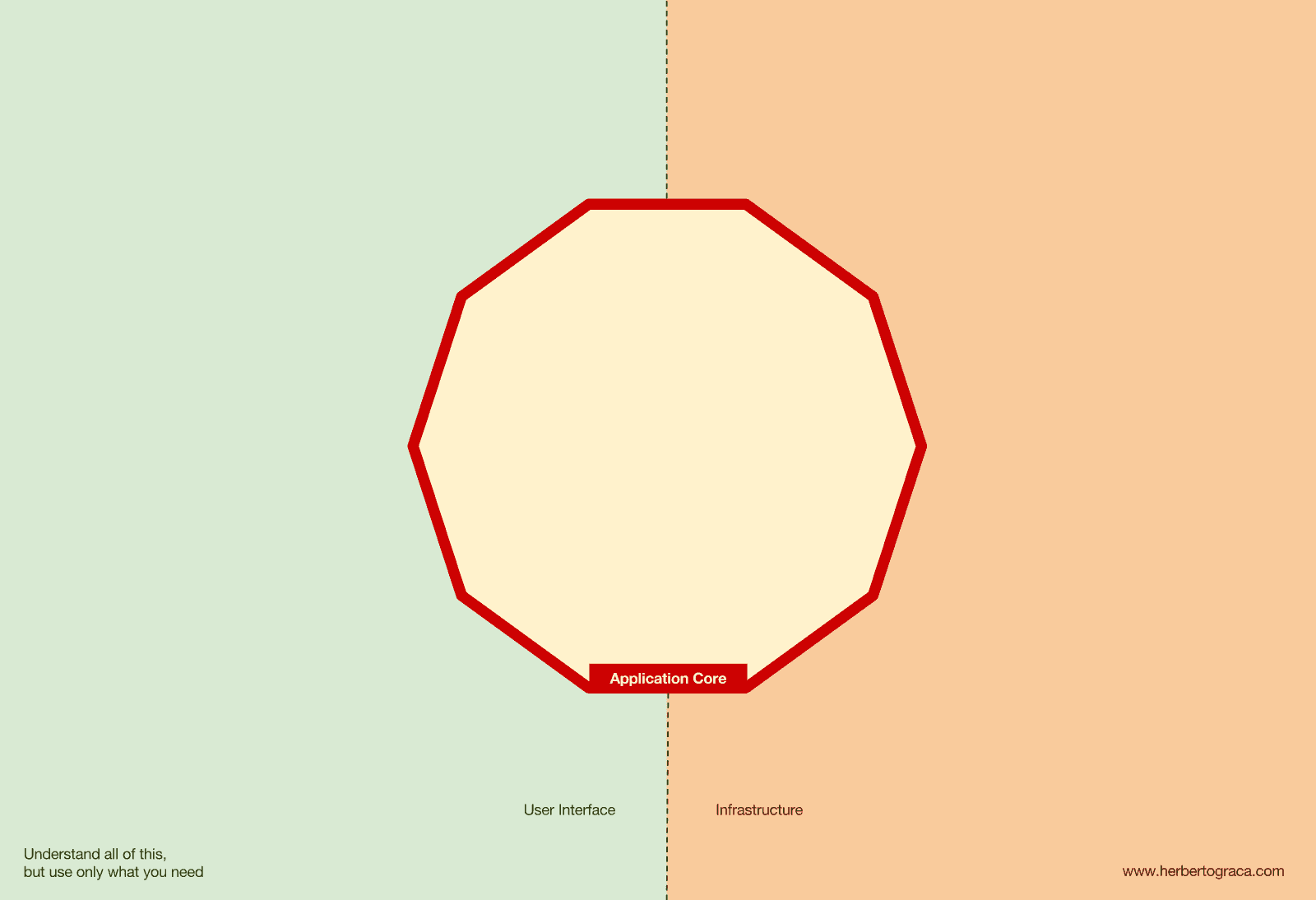
우리가 정말 중요하게 생각해야 할 부분은 바로 애플리케이션 코어입니다. 이곳에 있는 코드가 바로 우리의 애플리케이션이며, 이 코드가 존재해야만 애플리케이션이 해야 하는 일들을 수행할 수 있습니다. 애플리케이션은 다양한 사용자 인터페이스(프로그레시브 웹 앱, 모바일 앱, CLI, API 등)를 통해 호출될 수 있지만, 실제 작업을 수행하는 코드는 모두 동일하며 애플리케이션 코어 안에 위치합니다. 따라서 어떤 UI가 작업을 시작하는지는 크게 중요하지 않습니다.
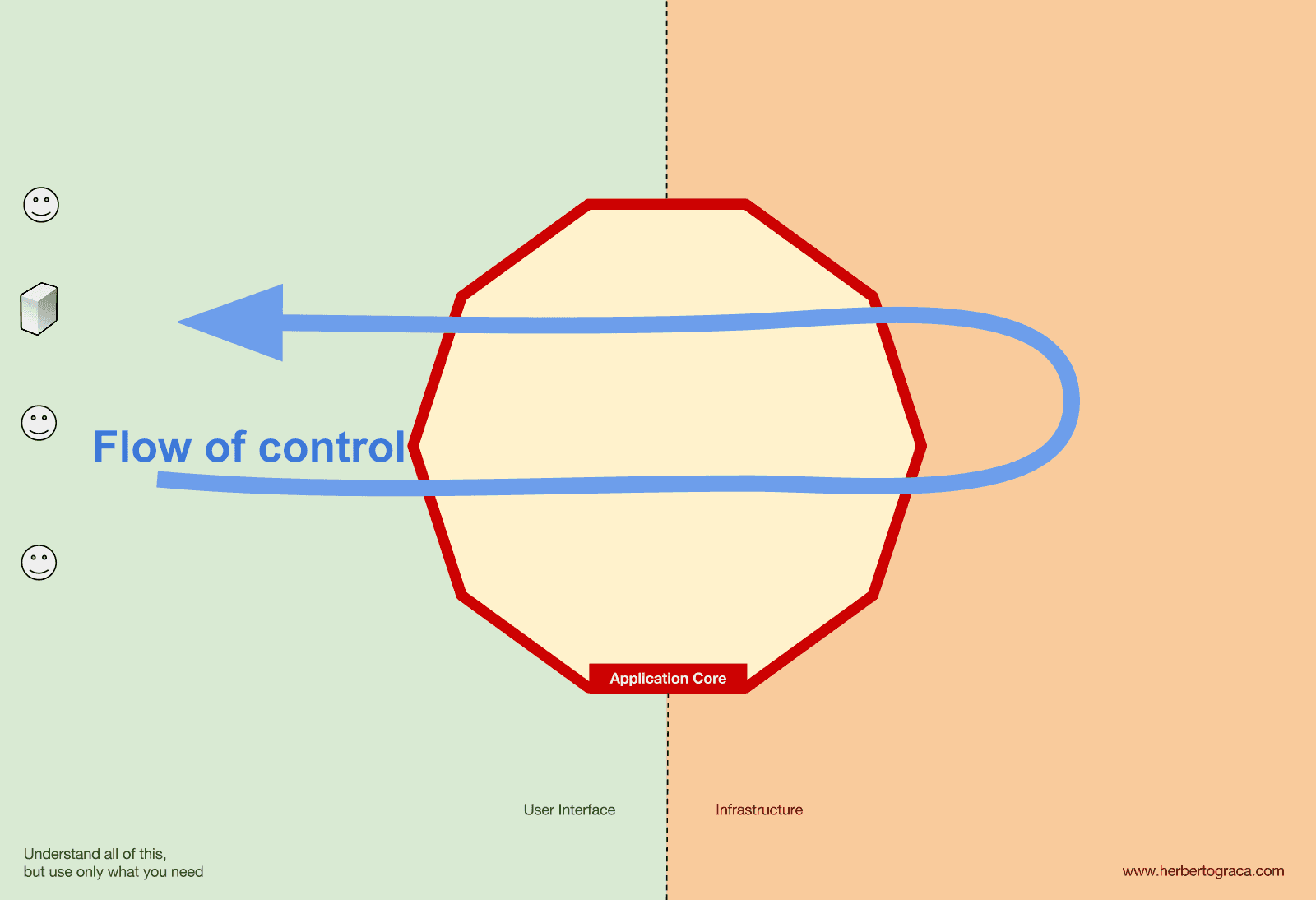
예상할 수 있듯, 일반적인 애플리케이션의 흐름은 다음과 같습니다.
- 사용자 인터페이스에서 시작된 요청이
- 애플리케이션 코어를 거쳐
- 인프라스트럭처 코드로 전달된 후
- 다시 애플리케이션 코어로 돌아와서 최종적으로 처리된 응답을
- 사용자 인터페이스에 전달합니다.
도구
우리 시스템의 핵심인 애플리케이션 코어로부터 멀리 떨어져 있는 곳에는 애플리케이션에서 사용하는 여러 가지 도구들이 있습니다. 예를 들어 데이터베이스 엔진, 검색 엔진, 웹 서버 또는 CLI 콘솔 같은 것들입니다. (물론 웹 서버와 CLI는 전달 메커니즘(delivery mechanism)으로도 분류됩니다.)
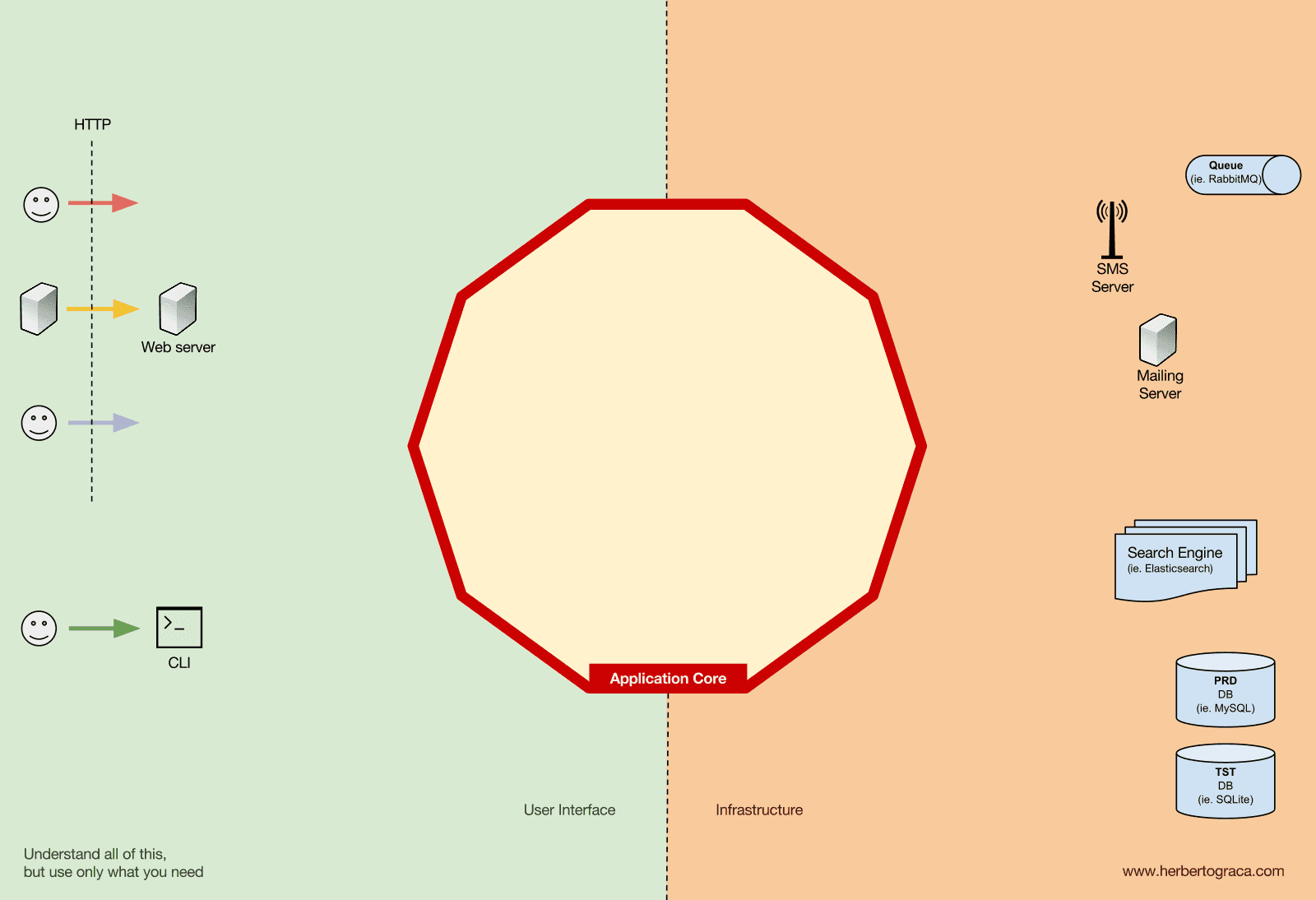
CLI 콘솔과 데이터베이스 엔진을 같은 “양동이”에 넣는 것이 어색할 수 있지만, 목적이 서로 다르더라도 결국 애플리케이션에서 사용하는 도구라는 점은 같습니다. 주요한 차이는 다음과 같습니다.
- CLI 콘솔이나 웹 서버는 애플리케이션에게 무언가를 하라고 지시하는 역할입니다.
- 반면, 데이터베이스 엔진은 애플리케이션으로부터 무언가를 하라는 지시를 받습니다.
이 차이는 매우 중요합니다. 왜냐하면 이것이 바로 애플리케이션 코어와 이러한 도구들을 연결하는 코드를 작성할 때 큰 영향을 미치기 때문입니다.
도구 및 전달 메커니즘을 애플리케이션 코어와 연결하기
도구를 애플리케이션 코어와 연결하는 코드 단위를 어댑터(adapter) 라고 부릅니다(포트 & 어댑터 아키텍처). 어댑터는 특정 도구와 비즈니스 로직 간에 양방향으로 커뮤니케이션할 수 있게 하는 코드 구현체입니다.
애플리케이션에 무언가를 하라고 지시하는 어댑터를 기본 어댑터(Primary Adapter) 또는 주도하는 어댑터(Driving Adapter) 라고 하고, 애플리케이션으로부터 무언가를 하라는 지시를 받는 어댑터를 보조 어댑터(Secondary Adapter) 또는 주도되는 어댑터(Driven Adapter) 라고 합니다.
포트(Ports)
하지만 이러한 어댑터들은 무작위로 생성되는 것이 아닙니다. 각 어댑터는 애플리케이션 코어로의 특정한 진입점인 포트(Port) 를 통해 연결됩니다. 포트는 단순히 도구가 애플리케이션 코어를 사용하는 방식, 혹은 애플리케이션 코어가 도구를 사용하는 방식을 명시한 사양(specification)입니다. 대부분의 프로그래밍 언어에서는 가장 간단한 형태로 이 사양(포트)을 인터페이스(interface) 로 정의하지만, 실제로는 여러 개의 인터페이스와 DTO로 구성될 수도 있습니다.
여기서 주목해야 할 중요한 점은, 포트(인터페이스)는 비즈니스 로직 내부에 속하며, 어댑터는 외부에 위치한다는 것입니다. 이 패턴이 제대로 동작하기 위해서는 도구의 API를 단순히 모방하는 것이 아니라 애플리케이션 코어의 요구사항에 맞춰 포트를 만드는 것이 매우 중요합니다.
기본 어댑터(Primary 또는 Driving Adapters)
기본 어댑터(주도하는 어댑터)는 포트를 감싸고(wrap) 이를 통해 애플리케이션 코어에 해야 할 작업을 전달합니다. 다시 말해, 전달 메커니즘(웹서버, CLI 등)을 통해 들어오는 데이터를 애플리케이션 코어의 메서드 호출로 변환하는 역할을 합니다.
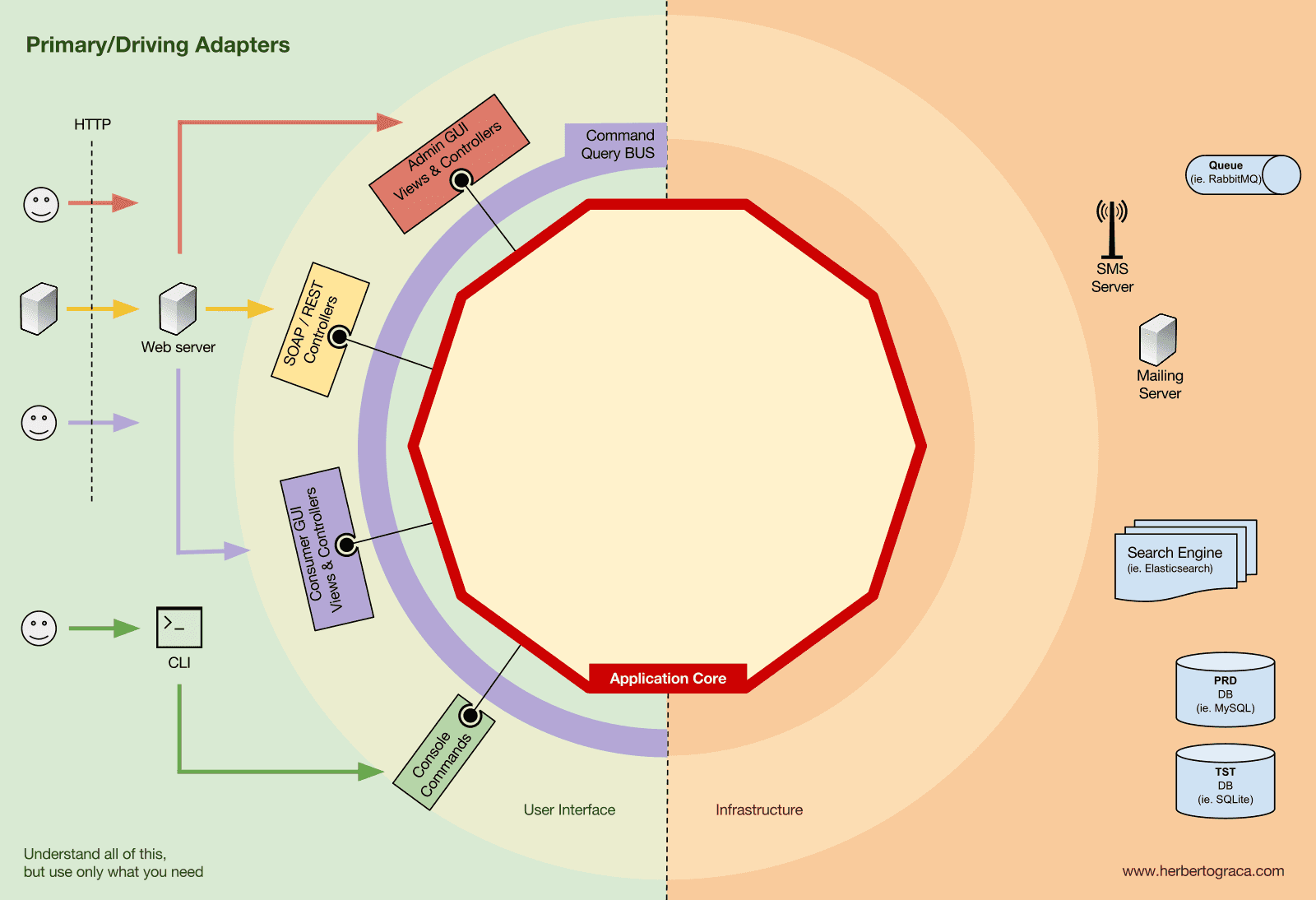
좀 더 명확하게 설명하면, 기본 어댑터는 보통 컨트롤러(Controllers) 또는 콘솔 명령(Console Commands)이며, 이들의 생성자(constructor)에는 필요한 인터페이스(포트)를 구현한 객체가 주입(inject)됩니다.
더 구체적인 예시를 들어보겠습니다. • 포트는 컨트롤러가 필요로 하는 서비스(Service) 인터페이스나 리포지토리(Repository) 인터페이스일 수 있습니다. 그러면 컨트롤러에는 이 서비스나 리포지토리를 구현한 구체적인 클래스가 주입되고, 이를 사용하여 비즈니스 로직을 호출하게 됩니다. • 또 다른 예로, 포트가 커맨드 버스(Command Bus)나 쿼리 버스(Query Bus) 인터페이스일 수 있습니다. 이 경우 컨트롤러에는 커맨드 버스나 쿼리 버스의 구체적인 구현체가 주입되고, 컨트롤러는 적절한 커맨드나 쿼리를 생성하여 해당 버스에 전달합니다.
보조 어댑터(Secondary 또는 Driven Adapters)
기본 어댑터가 포트를 감싸는 형태인 것과 달리, 보조 어댑터(주도되는 어댑터)는 포트(인터페이스)를 직접 구현한 다음, 이 포트가 필요한 위치(타입 힌트로 지정된)에 주입됩니다.
간단한 예를 들어 보겠습니다.
데이터를 저장하는 간단한 애플리케이션이 있다고 가정해 봅시다. 우리는 데이터를 저장하고 특정 ID로 데이터를 삭제하는 메서드를 갖는 저장 인터페이스(persistence interface)를 먼저 만듭니다. 이후 우리 애플리케이션에서 데이터를 저장하거나 삭제할 때마다 생성자에서 이 저장 인터페이스를 구현한 객체를 필요로 하게 됩니다.
이제 MySQL 데이터베이스를 사용하는 구체적인 어댑터를 만들어 봅니다. 이 어댑터는 저장 인터페이스를 구현하여 데이터를 실제로 저장하거나 삭제하는 메서드를 제공하고, 애플리케이션 내에서 저장 인터페이스가 필요할 때마다 이 MySQL 어댑터를 주입해 사용합니다.
나중에 데이터베이스를 PostgreSQL이나 MongoDB로 바꾸고 싶다면, 새로운 데이터베이스에 맞게 저장 인터페이스를 구현한 새로운 어댑터를 만들고 기존 어댑터 대신 새로운 어댑터를 주입하기만 하면 됩니다.
제어의 역전(Inversion of Control)
이 패턴에서 주목해야 할 특징은, 어댑터가 특정한 도구와 특정한 포트(인터페이스 구현)에 의존한다는 점입니다. 하지만 비즈니스 로직(애플리케이션 코어)은 오직 자신에게 맞게 설계된 포트(인터페이스)에만 의존할 뿐, 특정한 어댑터나 도구에는 의존하지 않습니다.
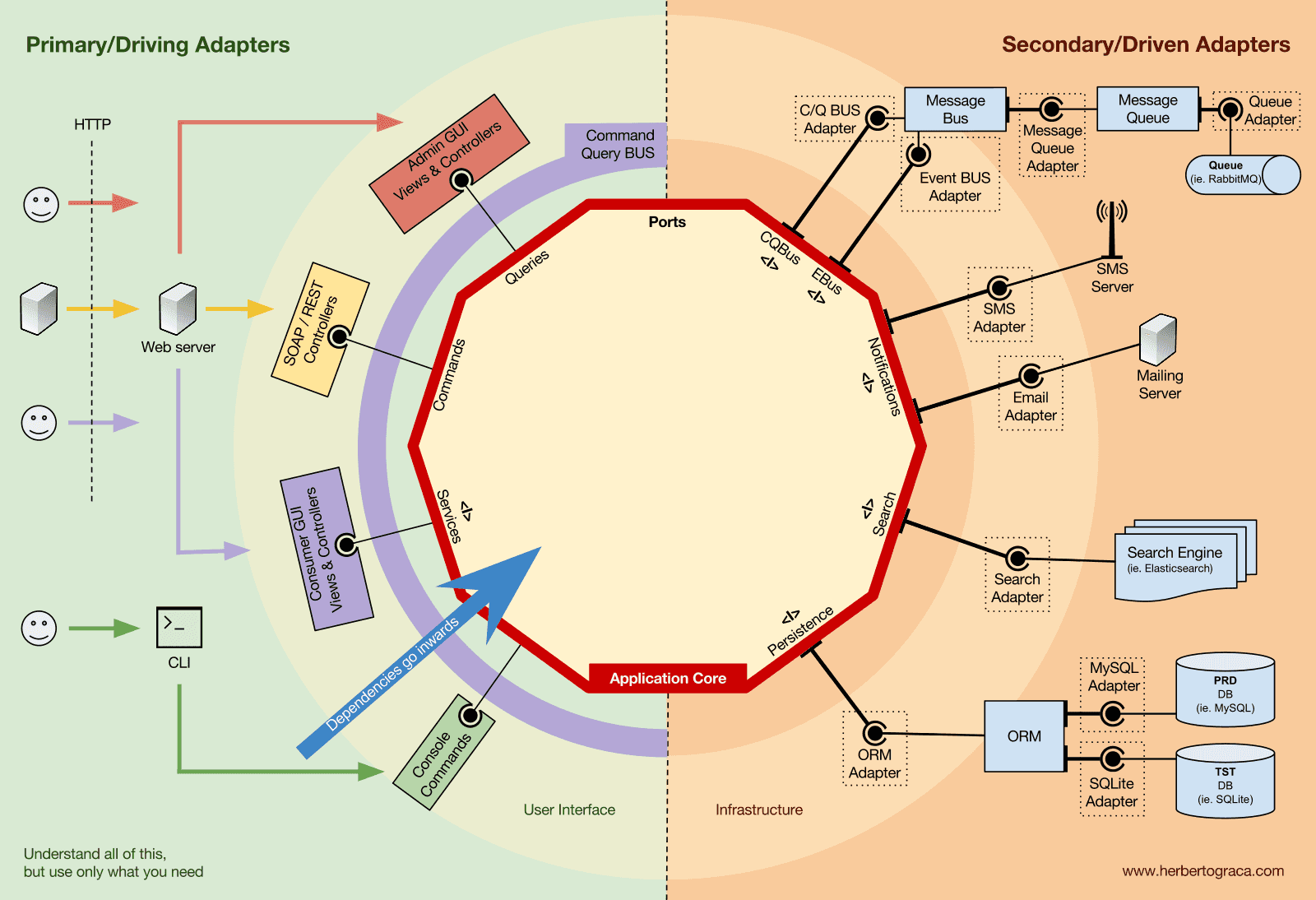
이는 의존성의 방향이 애플리케이션 중심을 향한다는 뜻이며, 아키텍처 레벨에서의 제어의 역전(Inversion of Control, IoC) 원칙을 따르고 있음을 의미합니다.
다시 한 번 강조하지만, 포트를 설계할 때는 단순히 도구의 API를 따라 만드는 것이 아니라, 반드시 애플리케이션 코어의 필요에 따라 설계해야 합니다.
애플리케이션 코어의 조직화(Application Core Organisation)
어니언 아키텍처(Onion Architecture)는 DDD(도메인 주도 설계)의 계층 구조를 포트 & 어댑터 아키텍처와 결합하여 사용합니다. 이 계층들은 비즈니스 로직, 즉 포트 & 어댑터 아키텍처의 내부(“헥사곤”)에 좀 더 명확한 구조를 제공하기 위한 것이며, 포트 & 어댑터 아키텍처와 마찬가지로 모든 의존성의 방향은 내부 중심을 향합니다.
애플리케이션 계층(Application Layer)
유스케이스(use case)는 우리 애플리케이션에서 하나 이상의 사용자 인터페이스(UI)에 의해 애플리케이션 코어 내에서 호출될 수 있는 프로세스를 의미합니다. 예를 들어 CMS 애플리케이션이라면, 일반 사용자를 위한 메인 애플리케이션 UI가 있을 수 있고, CMS 관리자를 위한 별도의 UI, CLI 인터페이스, 웹 API가 별개로 존재할 수도 있습니다. 이 각각의 UI(애플리케이션)는 자신만의 특정한 유스케이스를 실행하거나, 여러 UI가 공통으로 사용하는 유스케이스를 실행할 수도 있습니다.
이러한 유스케이스는 DDD에서 제공하고 어니언 아키텍처에서 채택한 가장 첫 번째 계층인 애플리케이션 계층(Application Layer)에서 정의됩니다.
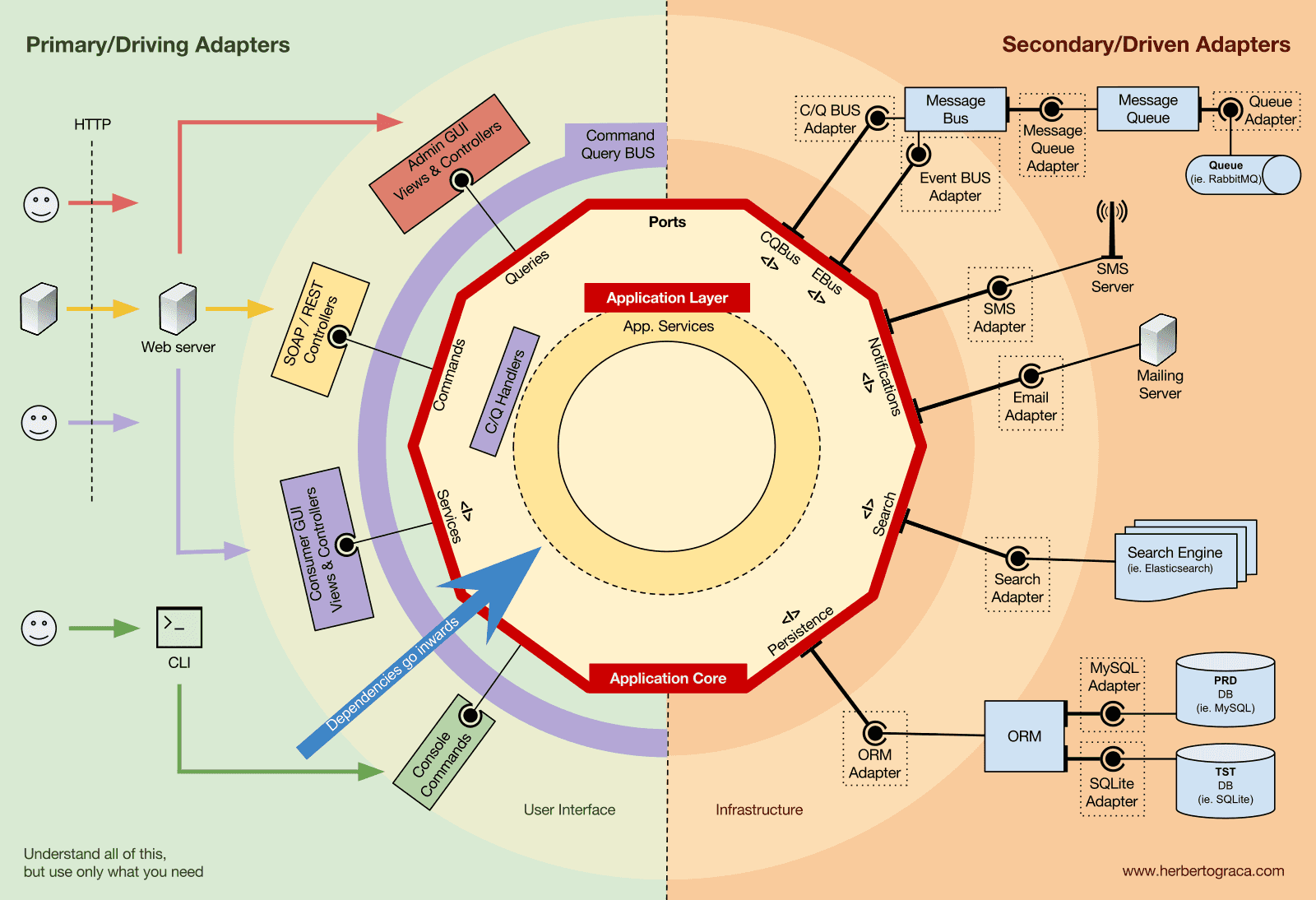
이 계층의 주된 요소는 애플리케이션 서비스(Application Services)와 그 인터페이스들이지만, 또한 ORM 인터페이스, 검색엔진 인터페이스, 메시징 인터페이스 등과 같은 포트 & 어댑터 인터페이스(포트)들도 포함됩니다. 우리가 커맨드 버스나 쿼리 버스를 사용하는 경우, 커맨드와 쿼리를 처리하는 핸들러(Handlers) 역시 바로 이 계층에 위치합니다.
애플리케이션 서비스나 커맨드 핸들러는 유스케이스, 즉 비즈니스 프로세스를 실행하는 로직을 포함합니다. 일반적으로 이들의 역할은 다음과 같습니다.
- 리포지토리(Repository)를 이용해 하나 이상의 엔티티를 찾고,
- 이 엔티티들에게 도메인 로직 수행을 지시한 뒤,
- 다시 리포지토리를 통해 엔티티를 저장하여 데이터 변경사항을 영속화하는 것입니다.
커맨드 핸들러는 두 가지 방식으로 사용될 수 있습니다.
- 실제 유스케이스를 수행하는 로직을 직접 담을 수도 있고,
- 또는 단순히 아키텍처 내에서 유스케이스를 연결해주는 연결 고리(wiring piece)로 사용될 수도 있습니다. 이 경우 커맨드를 받아 애플리케이션 서비스 내의 로직을 실행하는 역할만 합니다.
어떤 방식을 선택할지는 다음과 같은 상황에 따라 달라질 수 있습니다.
- 이미 애플리케이션 서비스가 존재하고, 이후에 커맨드 버스를 추가하는 경우인지?
- 커맨드 버스가 임의의 클래스/메서드를 핸들러로 사용할 수 있게 허용하는지, 아니면 특정 클래스를 상속하거나 특정 인터페이스를 구현해야만 하는지에 따라 결정됩니다.
이 계층은 또한 유스케이스가 완료된 결과로 발생하는 애플리케이션 이벤트(Application Events) 를 실행시키는 역할도 합니다. 이 이벤트는 유스케이스가 발생시킨 부수적 효과(side effect)를 처리하는 로직을 호출하는 데 사용됩니다. 예를 들어 이메일 전송, 제3자 API에 알림 전송, 푸시 알림 전송, 심지어 다른 컴포넌트의 다른 유스케이스 실행 등을 말합니다.
도메인 계층(Domain Layer)
한 단계 더 내부로 들어가면 도메인 계층(Domain Layer)이 존재합니다. 이 계층의 객체들은 도메인 자체에 특화된 데이터와 이 데이터를 조작하는 도메인 로직을 담고 있으며, 애플리케이션 계층에서 이를 호출하는 비즈니스 프로세스와는 독립적입니다. 즉, 도메인 계층의 객체들은 애플리케이션 계층의 존재조차 모른 채 독립적으로 동작합니다.
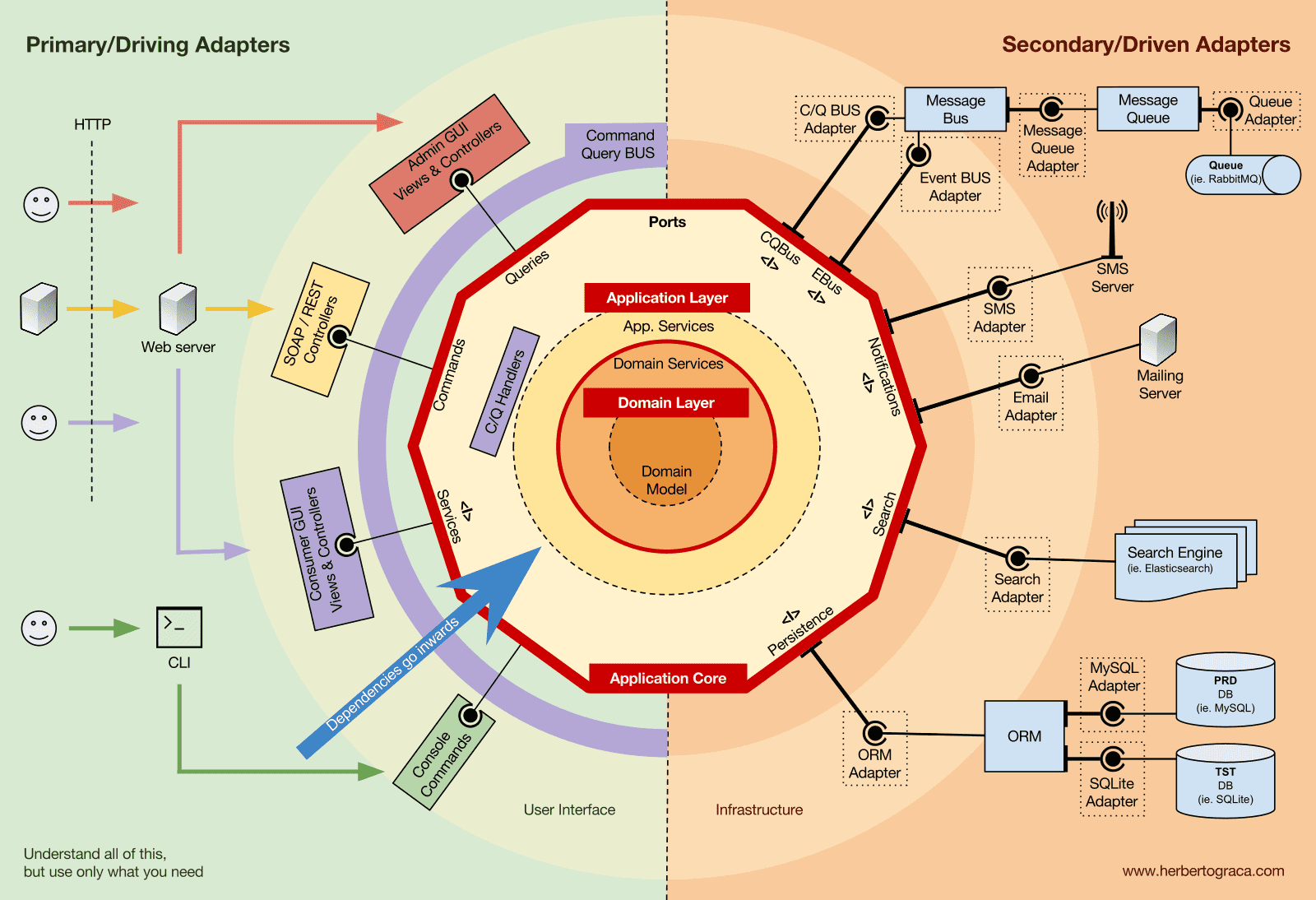
도메인 서비스(Domain Services)
앞서 언급했듯이, 애플리케이션 서비스의 역할은 보통 다음과 같습니다.
- 리포지토리를 통해 엔티티를 찾고,
- 엔티티에 도메인 로직을 수행하도록 지시하고,
- 다시 리포지토리를 통해 엔티티의 변경사항을 저장합니다.
하지만 때때로 여러 엔티티(같은 유형이든 다른 유형이든)를 포함하는 도메인 로직이 발생하는 경우, 이 로직이 각 개별 엔티티에 직접적으로 속하지 않는다고 판단될 수 있습니다. 즉, 엔티티가 직접 책임질 필요는 없는 로직이 등장하는 것입니다.
이때 일반적으로 처음 떠오르는 방법은 애플리케이션 서비스에 이 로직을 위치시키는 것입니다. 그러나 이렇게 하면 이 로직은 다른 유스케이스에서 재사용하기 어려워집니다. 즉, 도메인 로직은 애플리케이션 계층에 있어서는 안 됩니다.
이 문제를 해결하는 방법은 도메인 서비스(Domain Service) 를 만드는 것입니다. 도메인 서비스는 여러 엔티티를 받아 그 위에서 도메인 로직을 수행하는 역할을 합니다. 도메인 서비스는 도메인 계층에 속하기 때문에 애플리케이션 계층의 클래스들(애플리케이션 서비스나 리포지토리)에 대해 전혀 알지 못합니다. 대신, 도메인 서비스는 다른 도메인 서비스 또는 도메인 모델 객체를 사용할 수 있습니다.
도메인 모델(Domain Model)
아키텍처의 가장 중앙, 즉 외부의 어떤 것에도 의존하지 않는 중심부에는 도메인 모델(Domain Model)이 있습니다. 도메인 모델에는 엔티티(Entity)를 포함하여, 값 객체(Value Object), 열거형(Enum), 그리고 도메인을 표현하는 모든 비즈니스 객체가 존재합니다.
또한, 도메인 모델에는 데이터가 특정 방식으로 변경될 때 발생하는 도메인 이벤트(Domain Events) 가 포함됩니다. 어떤 엔티티의 데이터가 변경될 때마다 도메인 이벤트가 발생하여, 변경된 속성의 새로운 값을 함께 전달합니다. 이는 예를 들어 이벤트 소싱(Event Sourcing)에 사용하기에도 매우 적합합니다.
컴포넌트(Components)
지금까지는 코드의 계층(layers)을 기준으로 코드를 나누는 방법을 이야기했습니다. 하지만 이것은 비교적 세부적인 코드 분리 방법입니다. 이와는 별개로, 더 넓은 관점에서 코드를 분리하는 방법이 있으며, 그것은 하위 도메인(sub-domain)이나 바운디드 컨텍스트(bounded context)를 기준으로 나누는 방식입니다. 로버트 C. 마틴(Robert C. Martin)은 이를 두고 소리치는 아키텍처(screaming architecture)라고 표현한 바 있습니다. 이것은 흔히 ‘기능별 패키징(package by feature)’ 또는 ’컴포넌트별 패키징(package by component)’이라고 불리며, 계층별 패키징(package by layer)의 반대 개념입니다. 사이먼 브라운(Simon Brown)의 블로그 포스트 “Package by component and architecturally-aligned testing” 에서 이 개념을 아주 잘 설명하고 있습니다.
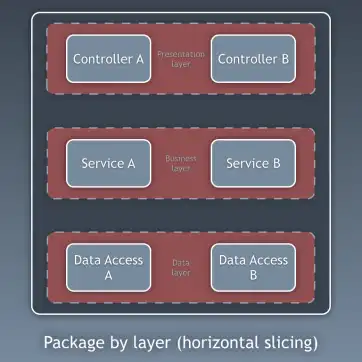
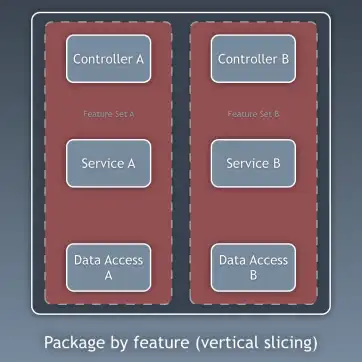
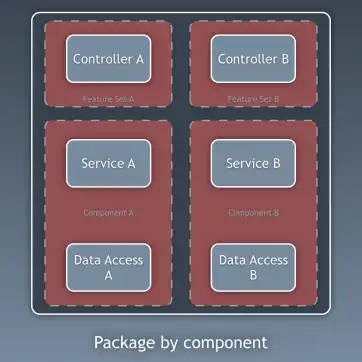
저는 개인적으로 “컴포넌트별 패키징(package by component)” 방식을 선호하며, 사이먼 브라운의 다이어그램을 빌려 제 방식대로 수정하여 다음과 같이 표현합니다.
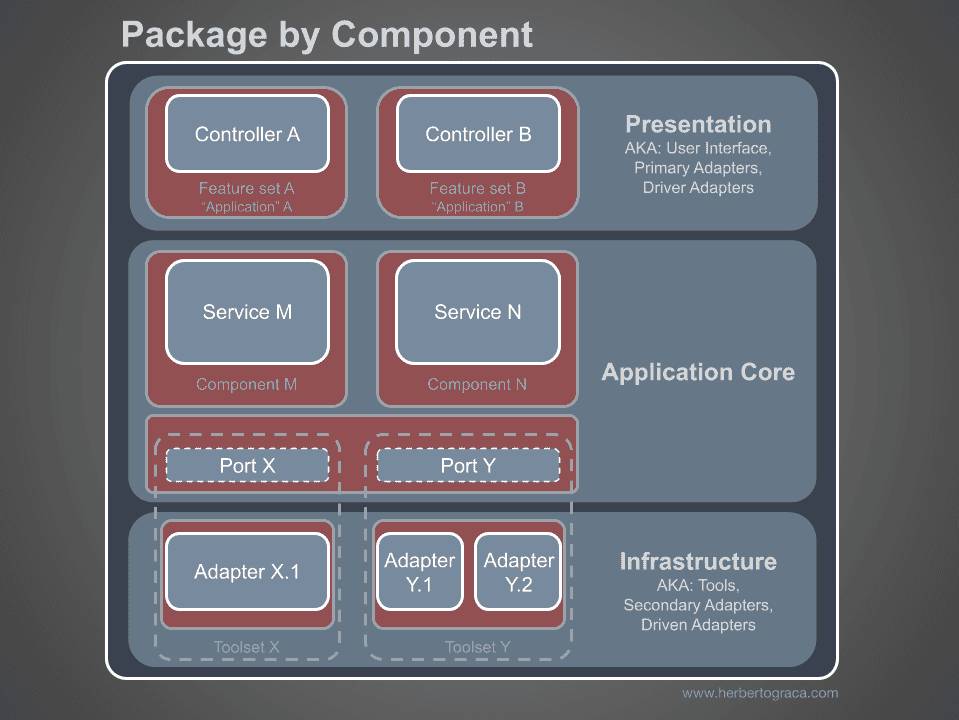
이러한 컴포넌트는 앞서 설명한 계층(layer)을 가로지르는 구조를 갖습니다. 즉, 각 컴포넌트는 도메인과 밀접히 관련되어 있으며, 예시로는 인증(Authentication), 권한부여(Authorization), 결제(Billing), 사용자(User), 리뷰(Review), 계정(Account)과 같은 것이 있습니다. 특히 권한부여나 인증과 같은 바운디드 컨텍스트는 외부 도구로 보고 이를 어댑터로 감싸 포트를 통해 접근하게 만듭니다.
컴포넌트 간의 결합도 낮추기(Decoupling the components)
미세한 코드 단위(클래스, 인터페이스, 트레잇, 믹스인 등)뿐 아니라, 컴포넌트와 같은 좀 더 거시적인 코드 단위도 결합도는 낮고 응집도는 높은 상태가 이상적입니다.
클래스 간 결합도를 낮추기 위해 우리는 의존성 주입(Dependency Injection) 을 사용하여 클래스 내부에서 직접 의존성을 생성하는 대신, 외부로부터 의존성을 주입받습니다. 또한 의존성 역전 원칙(Dependency Inversion) 을 사용하여 구체적인 클래스 대신 추상화(인터페이스나 추상 클래스)에 의존하도록 만듭니다. 이렇게 하면 의존성을 가진 클래스는 사용하는 구체적인 클래스에 대해 알지 못하며, 의존하는 클래스의 정확한 이름조차도 알 필요가 없습니다.
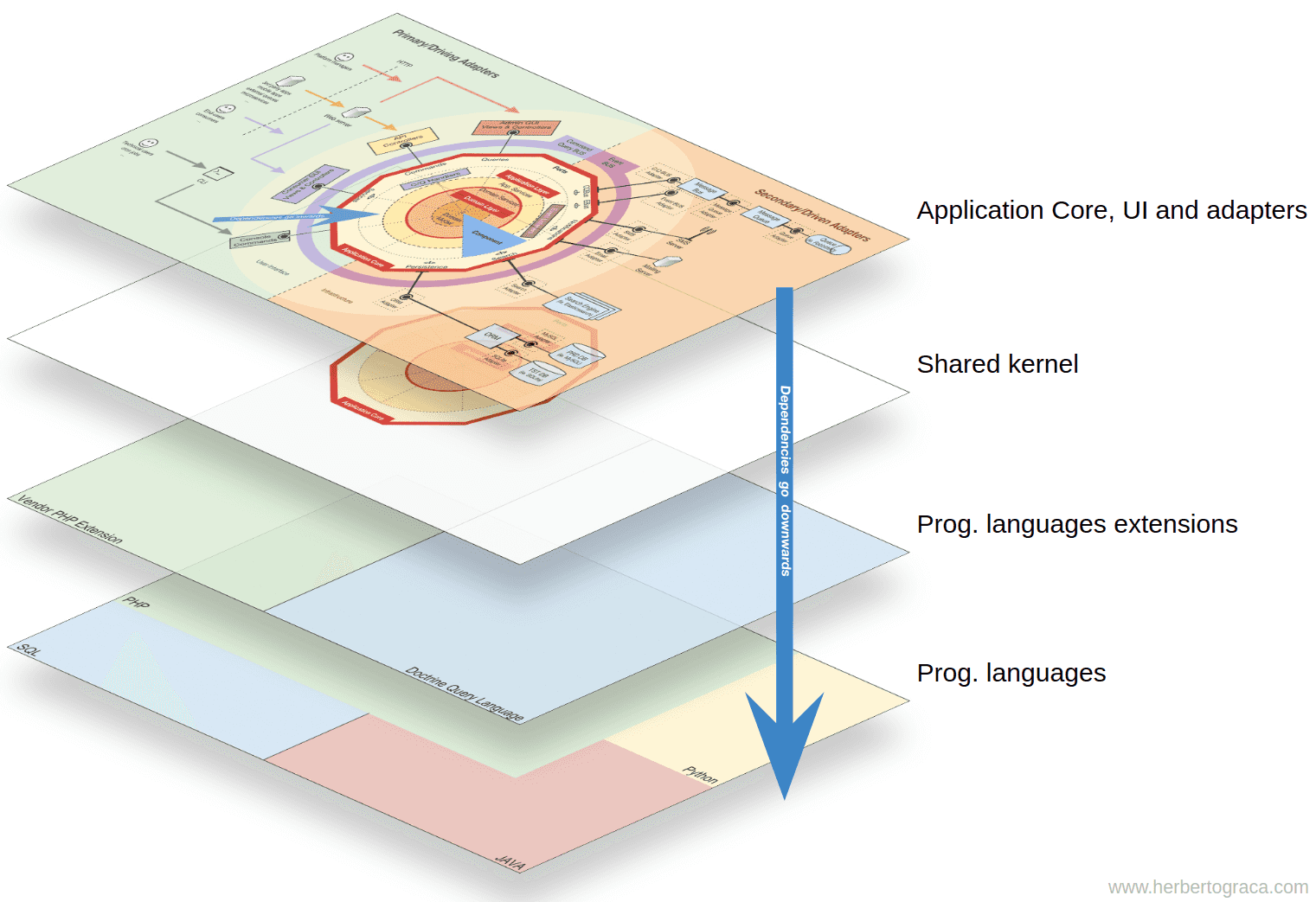
마찬가지로, 완전히 결합도가 낮은 컴포넌트는 다른 컴포넌트에 대해 직접적인 지식(심지어 인터페이스조차도)이 없습니다. 이는 단지 의존성 주입이나 의존성 역전 원칙만으로는 부족하며, 별도의 아키텍처적 구조가 필요하다는 의미입니다. 우리는 이를 위해 이벤트(Event), 공유 커널(Shared Kernel), 최종 일관성(Eventual Consistency), 또는 서비스 디스커버리(Discovery Service) 같은 추가적인 구조를 필요로 할 수 있습니다.
다른 컴포넌트의 로직을 실행하기(Triggering logic in other components)
한 컴포넌트(컴포넌트 B)에서 다른 컴포넌트(컴포넌트 A)에 어떤 일이 발생했을 때 특정 작업을 수행하고자 한다면, A에서 직접적으로 B의 클래스나 메서드를 호출할 수는 없습니다. 그렇게 하면 A가 B에 직접 의존하게 되기 때문입니다.
대신 A는 이벤트 디스패처(Event Dispatcher)를 사용하여 애플리케이션 이벤트를 발행(dispatch)하고, 이 이벤트를 듣고 있는 모든 컴포넌트(B 포함)는 해당 이벤트를 받아 원하는 작업을 수행합니다. 이렇게 하면 컴포넌트 A는 이벤트 디스패처에 의존하게 되지만, 컴포넌트 B와의 결합도는 낮출 수 있습니다.
하지만 이벤트 자체가 컴포넌트 A에 정의되어 있다면, B는 여전히 A의 존재에 대해 알게 되고, 여전히 A에 결합된 상태입니다. 이러한 의존성을 제거하기 위해 우리는 모든 컴포넌트가 공유하는 핵심적인 기능을 포함하는 별도의 라이브러리인 공유 커널(Shared Kernel) 을 만들 수 있습니다. 그러면 컴포넌트들은 공유 커널에만 의존하게 되며 서로 간에는 결합되지 않습니다. 공유 커널은 애플리케이션 이벤트, 도메인 이벤트뿐 아니라 스펙(Specification) 객체 등 공유가 의미 있는 요소를 담고 있습니다. 하지만 공유 커널이 변경되면 모든 컴포넌트에 영향을 주기 때문에 가능한 한 최소화하는 것이 좋습니다. 또한 다양한 프로그래밍 언어를 사용하는 폴리글랏 시스템(마이크로서비스 등)에서는, 공유 커널이 언어 중립적(JSON 등)이어야 하며, 각 컴포넌트는 이 중립적 정의를 기반으로 구체적 구현을 자동 생성할 수도 있습니다. (More then concentric layers)
이러한 접근은 모놀리식(monolithic) 애플리케이션과 마이크로서비스 같은 분산 시스템 모두에서 효과적입니다. 하지만 이벤트 전달이 비동기적(asynchronous)으로만 가능할 때, 즉 다른 컴포넌트의 로직을 즉시 실행해야 할 때는 충분하지 않습니다. 이럴 때 컴포넌트 A는 컴포넌트 B에 직접적인 HTTP 요청을 보내야 하며, 이때는 컴포넌트 간 결합도를 낮추기 위해 서비스 디스커버리(discovery service)를 통해 대상 컴포넌트의 위치를 찾거나, 서비스 디스커버리가 요청을 중계(proxy)하여 최종 응답을 반환하도록 할 수 있습니다.
다른 컴포넌트의 데이터 얻기(Getting data from other components)
컴포넌트가 자신이 소유하지 않은 데이터를 직접 변경하는 것은 허용되지 않습니다. 그러나 자신이 소유하지 않은 데이터를 조회하여 사용하는 것은 허용될 수 있습니다.
공유된 데이터 저장소(Data storage shared between components)
한 컴포넌트(예: Billing)가 다른 컴포넌트(예: Account)의 데이터를 사용할 필요가 있다면, Billing 컴포넌트는 쿼리 객체(Query object)를 이용해 데이터를 저장소로부터 조회합니다. 이 방식에서 Billing 컴포넌트는 모든 데이터셋의 존재에 대해 알 수 있지만, 자신이 소유하지 않은 데이터를 읽기 전용(read-only)으로만 사용할 수 있습니다.
컴포넌트별로 분리된 데이터 저장소(Data storage segregated per component)
이 경우 동일한 원칙이 적용되지만, 데이터 저장소 수준에서의 복잡성이 증가합니다. 각 컴포넌트가 독자적인 데이터 저장소를 가지며, 저장소에는 다음이 존재합니다.
- 자신이 소유하고 있으며 변경할 수 있는 데이터(단일 진실의 원천, single source of truth)
- 다른 컴포넌트가 소유한 데이터의 복사본이며 변경할 수 없지만 컴포넌트 기능에 필요한 데이터(소유한 컴포넌트가 변경할 때마다 업데이트)
각 컴포넌트는 필요한 데이터의 로컬 복사본을 가지고 사용하며, 데이터의 소유 컴포넌트가 변경이 발생할 때마다 도메인 이벤트를 발행하면, 이를 듣고 있던 컴포넌트들이 해당 복사본을 즉시 업데이트합니다.
제어 흐름(Flow of control)
앞서 말했듯이, 제어 흐름은 기본적으로 사용자에서 출발해 애플리케이션 코어로 이동한 뒤, 인프라스트럭처 도구를 거쳐 다시 애플리케이션 코어로 돌아오고, 최종적으로 사용자에게 응답을 전달합니다. 그런데 구체적으로 클래스는 어떻게 연결되는 걸까요? 어떤 클래스가 어떤 클래스에 의존해야 할까요? 클래스들을 어떻게 구성해야 할까요?
이 질문에 답하기 위해, Uncle Bob이 클린 아키텍처(Clean Architecture) 글에서 사용한 방식을 참고하여, 다음 UML 스타일의 다이어그램으로 제어 흐름을 설명하겠습니다.
커맨드/쿼리 버스를 사용하지 않을 때(Without a Command/Query Bus)
커맨드 버스를 사용하지 않을 경우, 컨트롤러(Controller)는 애플리케이션 서비스(Application Service) 또는 쿼리 객체(Query object)에 의존하게 됩니다.
[2017-11-18 수정] 처음에는 쿼리 결과를 전달하는 데 사용하는 DTO를 빠트렸었는데, 이를 MorphineAdministered가 지적해 주어 추가하였습니다.
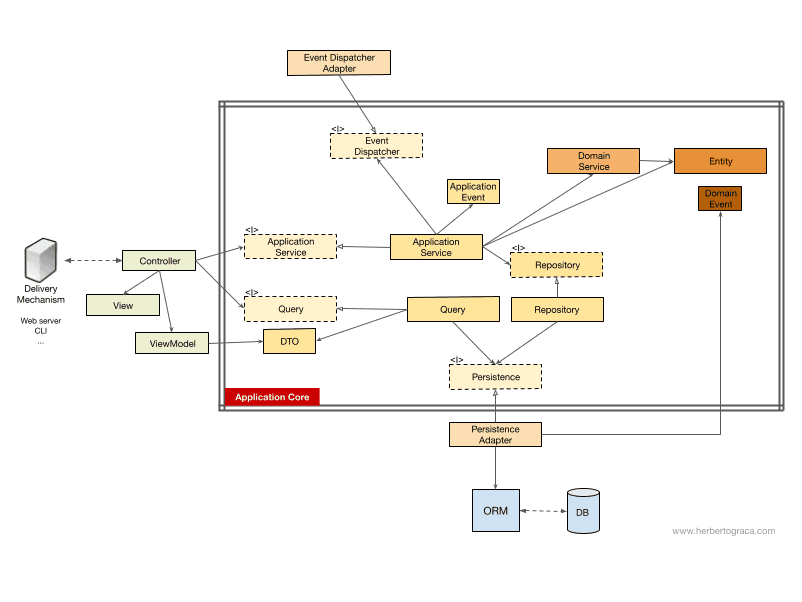
위의 다이어그램에서 애플리케이션 서비스에 인터페이스를 사용하고 있지만, 사실 애플리케이션 서비스가 애플리케이션 코드 내부에 존재하며 다른 구현체로 바꿀 가능성이 거의 없기 때문에 인터페이스가 반드시 필요하다고 보기는 어렵습니다. 물론 전체를 리팩토링하는 경우에는 필요할 수 있습니다.
쿼리 객체(Query object) 는 사용자에게 데이터를 보여주기 위해 최적화된 조회 로직만을 담고 있으며, 조회된 데이터는 DTO를 통해 반환되고 이를 뷰 모델(ViewModel)에 주입합니다. 뷰 모델은 화면에 표시할 데이터를 가공하는 로직을 포함할 수도 있고, 이를 통해 최종적으로 뷰(View)를 구성합니다.
반면, 애플리케이션 서비스(Application Service) 는 데이터를 단순히 조회하는 것 이상으로, 시스템에서 어떤 작업을 수행할 때 호출하는 유스케이스 로직을 담고 있습니다. 애플리케이션 서비스는 필요한 로직을 수행하는 엔티티(Entity)를 제공하는 리포지토리(Repository)에 의존합니다. 여러 엔티티가 관여하는 복잡한 도메인 프로세스를 조율할 때 도메인 서비스(Domain Service)를 사용할 수도 있지만, 실제로는 흔한 일은 아닙니다.
애플리케이션 서비스는 유스케이스 로직을 완료한 후, 이를 시스템에 알리기 위해 이벤트 디스패처(Event Dispatcher)를 통해 애플리케이션 이벤트를 발생시킬 수 있습니다.
여기서 흥미로운 점은 지속성 엔진(Persistence Engine, ORM 등)과 리포지토리에 각각 인터페이스를 두고 있다는 것입니다. 언뜻 보면 중복되어 보이지만, 이들은 목적이 서로 다릅니다.
- 지속성 인터페이스 는 ORM 위에 추상화된 계층을 제공하여, 사용하는 ORM을 바꾸더라도 애플리케이션 코어를 변경할 필요가 없게 합니다.
- 리포지토리 인터페이스 는 지속성 엔진 자체를 추상화합니다. 예를 들어 MySQL에서 MongoDB로 전환할 때, 지속성 인터페이스는 그대로 두고 같은 ORM을 계속 사용할 수도 있지만, 쿼리 언어 자체가 SQL과 완전히 다르기 때문에 새로운 리포지토리를 만들어야 합니다.
커맨드/쿼리 버스를 사용할 때(With a Command/Query Bus)
애플리케이션에서 커맨드/쿼리 버스를 사용하는 경우에도 다이어그램은 거의 같으며, 유일한 차이는 컨트롤러가 애플리케이션 서비스나 쿼리 객체 대신 버스(Bus) 와 커맨드(Command) 또는 쿼리(Query) 객체에 의존한다는 점입니다. 컨트롤러는 커맨드나 쿼리를 생성해 이를 버스로 전달하고, 버스는 이를 처리할 적절한 핸들러(Handler)를 찾아 실행합니다.
아래 다이어그램에서는 커맨드 핸들러가 다시 애플리케이션 서비스를 호출합니다. 하지만 대부분의 경우, 핸들러가 직접 유스케이스의 모든 로직을 포함합니다. 별도의 애플리케이션 서비스로 로직을 추출하는 경우는 같은 로직을 여러 핸들러에서 재사용할 필요가 있을 때뿐입니다.
[2017-11-18 수정] 처음에는 쿼리 결과를 전달하는 데 사용하는 DTO를 빠트렸었는데, 이를 MorphineAdministered가 지적해 주어 추가하였습니다.
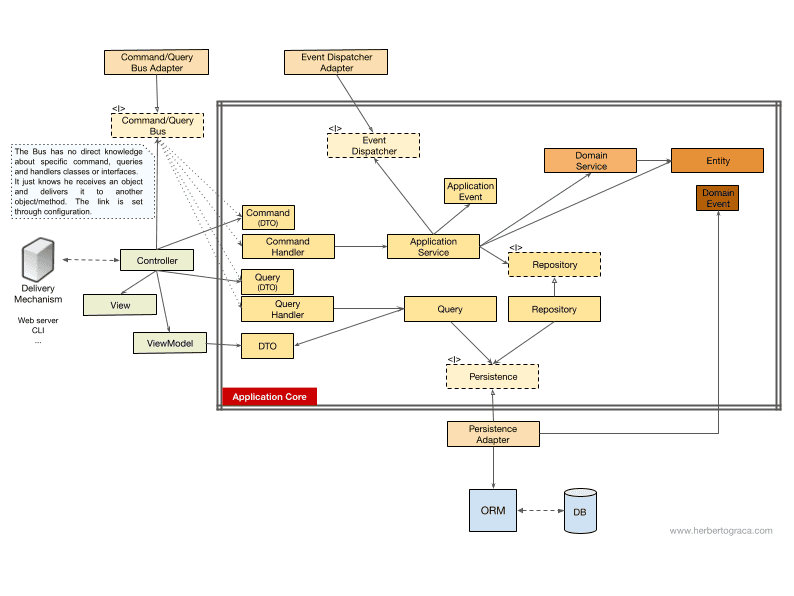
여기서 눈여겨볼 점은 버스(Bus)가 커맨드, 쿼리, 핸들러와 직접적인 의존성이 없다는 것입니다. 좋은 결합도(Decoupling)를 유지하려면 이들은 서로의 존재를 몰라야 하며, 버스가 어떤 커맨드나 쿼리를 어떤 핸들러가 처리해야 하는지에 대한 설정은 별도의 설정(configuration)을 통해 결정됩니다.
보시다시피, 두 경우 모두 애플리케이션 코어의 경계를 넘어가는 의존성 화살표는 항상 코어를 향해 안쪽으로 들어옵니다. 이는 포트 & 어댑터 아키텍처, 어니언 아키텍처, 클린 아키텍처의 가장 근본적인 원칙 중 하나입니다.

결론(Conclusion)
항상 그렇듯, 목표는 결합도는 낮고 응집도는 높은(loose coupling, high cohesion) 코드베이스를 만드는 것입니다. 그래야 코드 변경이 쉽고 빠르며 안전하게 이루어질 수 있습니다.
“계획 자체는 쓸모없지만, 계획하는 과정은 모든 것이다.” — 드와이트 아이젠하워(Eisenhower)
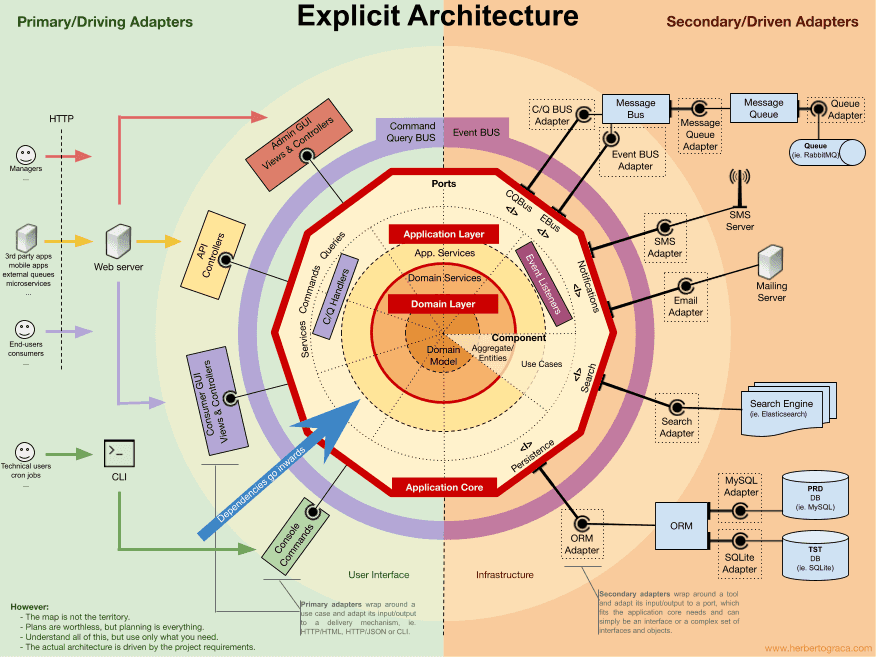
이 인포그래픽은 개념 지도(concept map)입니다. 여기서 제시한 개념들을 이해하고 숙지하면 더욱 건강한 아키텍처와 애플리케이션을 설계하는 데 도움을 줄 것입니다.
하지만, 다음 말을 꼭 기억해야 합니다.
“지도가 곧 영토는 아니다.” — 알프레드 코르지브스키(Alfred Korzybski)
즉, 위의 내용은 단지 가이드라인일 뿐입니다. 실제 애플리케이션이 우리가 적용하는 현실이며, 구체적인 유스케이스가 실제 아키텍처의 모습을 결정하게 됩니다.
우리는 이러한 패턴을 모두 이해해야 하지만, 동시에 우리 애플리케이션이 정확히 무엇을 필요로 하는지, 결합도를 낮추고 응집도를 높이기 위해 어디까지 갈 것인지를 지속적으로 고민해야 합니다. 이 결정은 프로젝트의 기능적 요구사항뿐 아니라 개발 기간, 애플리케이션의 수명, 개발팀의 경험 등 수많은 요소에 따라 달라집니다.
이것이 바로 제가 아키텍처를 이해하고 정리하는 방식입니다.
이 개념들은 제 다음 글인 More than concentric layers에서 더 확장하여 다뤘습니다.
하지만 실제 코드에서 어떻게 이러한 아키텍처와 도메인을 명시적으로 드러낼 수 있을까요? 그것은 제 다음 포스트에서 다룰 주제입니다.
마지막으로, 멋진 인포그래픽을 만드는 데 도움을 준 동료 Francesco Mastrogiacomo에게 감사의 말을 전합니다.
출처
DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together