EFK Stack, 그 중에 Fluentd와 Fluent Bit
EFK Stack으로 Docker Swarm Logging 구축
현재 사내에서는 컨테이너 오케스트레이션 툴로 Docker Swarm을 사용하고 있습니다. Kubernetes 전환 얘기가 솔솔 나오는 와중에 새로운 프로덕트를 내놓게 되었는데 이 과정에서 EFK를 사용하여 Logging을 구축한 경험, 특히 Fluent Bit과 Fluentd를 중심으로 기본 설정에 관해 이야기해볼까 합니다.
👀 ELK와 EFK Stack?
EFK란 Elasticsearch, Fluentd 그리고 Kibana의 첫 글자를 딴 약자입니다. 대표적으로 알려진 ELK는 Elasticsearch, Logstash 와 Kibana의 약자이며 두 Stack의 차이로는 로그 수집기를 Fluentd로 사용할 것인지 아니면 Logstash로 사용할 것인지 말고는 없습니다.
한 단계 더 가서 Logstash와 Fluentd의 차이점을 얘기해보자면 Logstash는 자바 런타임이 필요한 JRuby로 되어있으며 Fluentd는 자바 런타임이 필요하지 않은 CRuby로 되어있습니다. 그리고 Logstash에 비해 Fluentd는 조금 더 가벼우며 때에 따라 로그 전송만 담당하는, 더욱 경량화된 Fluent Bit을 사용 할 수 있습니다.
📐 Architecture
기본적인 구조는 아래와 같습니다.
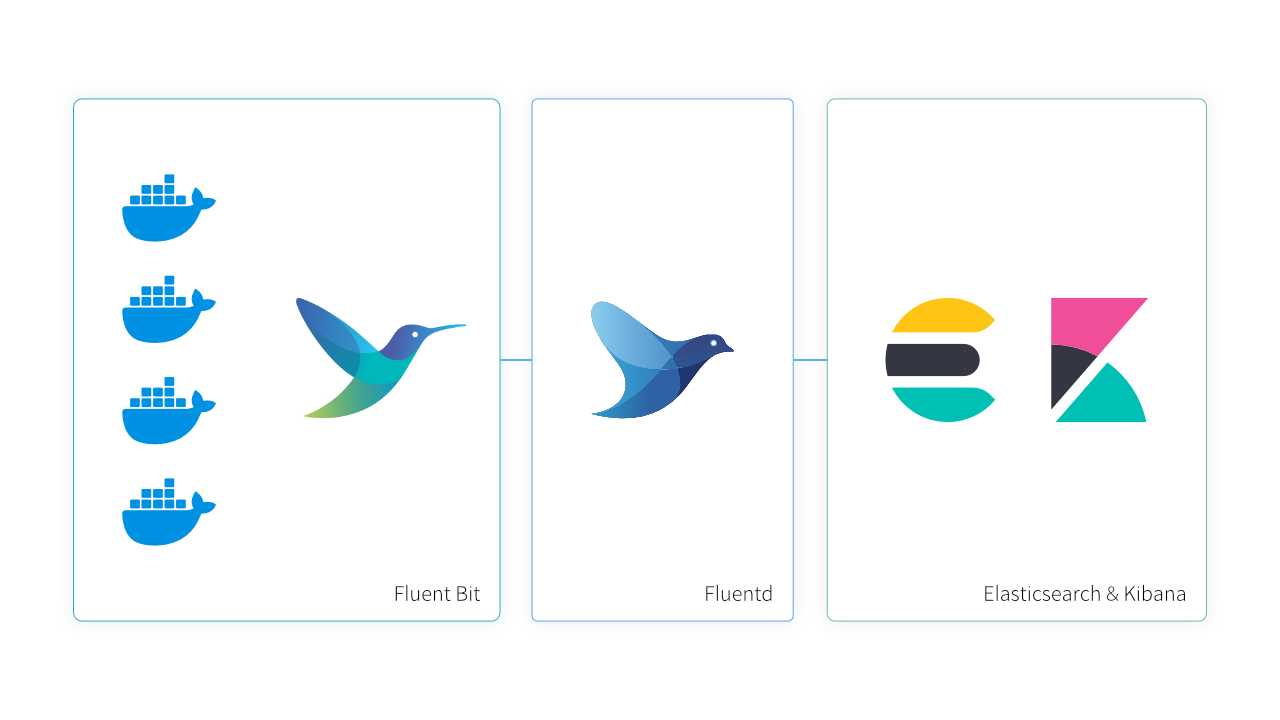
각 클라이언트에서 내부 네트워크로 구성된 서버에 Fluent Bit으로 log를 수집 후 외부 네트워크가 가능한 서버로 전송합니다. 데이터를 받는 서버에서는 Fluentd를 Aggregator의 역할로 구성하고 다시 Elasticsearch로 데이터를 전송, Kibana는 Elasticsearch의 데이터를 시각화합니다.
🤲 Fluent Bit과 Fluentd
앞서 언급했듯이 Fluent Bit은 Fluentd의 경량화된 버전으로 C로 만들어졌습니다. 서버 환경이 워낙 좋아져서 크게 상관은 없지만 서버에서 Forwarder만 담당한다면 좀 더 가벼운 Fluent Bit을 사용하는 것이 좋습니다.
👉 Input → Parser → Filter → Output
Fluent Bit과 Fluentd의 파이프라인은 중간중간 추가되는 과정이 있어서 조금은 다르지만 크게는 이러한 과정으로 진행됩니다.
- Input: 서로 다른 소스에서 어떤 데이터를 수집할 지 결정
- Parser: 수집하는 데이터를 구조화하는 파싱
- Filter: 데이터를 특정 대상으로 전달하기 전에 데이터를 가공
- Output: 가공된 데이터를 내보내는 방식을 정의
각 과정에서 다양한 플러그인들이 제공되며 설정을 정의함으로써 원하는 값을 도출하게끔 제어할 수 있습니다.
🚢 Forwarder (Fluent Bit)
프로덕트는 보안상의 이유로 여러 클라이언트에게 on-premise 형태로 제공하고 있습니다. 내부 네트워크로 구성된 서버에는 Docker Swarm으로 오케스트레이션 되니 먼저 많은 Docker들의 Log를 추적해야 했습니다. (Ubuntu 기준으로 Docker Log 위치는 /var/lib/docker/containers/<container id>/<container id>-json.log)
각 클라이언트 서버에선 Forwarder로만 사용하기에 Docker Build로 Fluent Bit를 설정하여 서비스합니다.
# inputs.conf
[INPUT]
Name tail
Parser docker
Path /var/lib/docker/containers/*/*.log
Docker_Mode On
Tag docker.<file_name>
Tag_Regex (?<file_name>[a-z0-9]*)-json.log
...Logging은 Docker 외에도 여러 개 Input을 작성하다 보면 설정 파일이 길어지게 됩니다. 거기에다 각종 Filter 등 다른 과정까지 포함하다 보면 하나의 설정 파일에 감당하기 어렵습니다. 그래서 각 과정을 @INCLUDE 를 사용하여 여러 파일로 모듈화를 하면 좋습니다.
# fluent-bit.conf
@INCLUDE /fluent-bit/etc/inputs.conf
@INCLUDE /fluent-bit/etc/filters.conf
...Docker Log를 이렇게 수집한 뒤 여러 Filter를 거쳐서 데이터를 원하는 형태로 가공해야 합니다. 그런고로 Filter야말로 핵심이라 할 수 있습니다.
무엇보다 Input 설정에서 Tag를 container id (file_name) 로 받기 때문에 각 Docker에서 나오는 Log를 인식할 수 있는 값으로 변환해야 하는 것이 중요합니다. 이를 위해 lua 스크립트를 사용해서 docker_metadata를 매칭한 뒤 태그를 변경하는 방법으로 필터링합니다.(참고 lua script)
# filters.conf
[FILTER]
Name lua
Match docker.*
script /fluent-bit/bin/docker-metadata.lua
call encrich_with_docker_metadata
[FILTER]
Name record_modifier
Match docker.*
Whitelist_key log
Whitelist_key docker.container_name
...
[FILTER]
Name modify
Match docker.*
Rename docker.container_name container_name
...
[FILTER]
Name rewrite_tag
Match docker.*
Rule $container_name (.*) docker.$0 false
...또한 grep을 써서 선택적으로 데이터를 취하거나 제외할 수 있습니다.
# filters.conf
[FILTER]
Name grep
Match docker.*
Exclude container_name (.*fluent).+
...이 후 Output에 forward로 Aggregator에게 데이터를 보내면 됩니다.
🗃 Aggregator (Fluentd)
각 클라이언트에서 저마다 보내오는 데이터를 Fluentd가 수집해서 Elasticsearch로 전송합니다. 이 역할은 한 곳에서만 담당하며 Elasticsearch와 Kibana를 같은 서버에서 함께 사용해도 됩니다.
Elasticsearch로 데이터를 전송하기 위해 Fluentd의 fluent-plugin-elasticsearch라는 플러그인의 설치가 우선되어야 합니다.
# Dockerfile
FROM fluent/fluentd:v1.11-1
USER root
RUN apk add --no-cache --update --virtual .build-deps \
sudo build-base ruby-dev \
&& sudo gem install \
fluent-plugin-concat \
fluent-plugin-elasticsearch \
&& apk del .build-deps \
&& rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem
COPY conf/* /fluentd/etc/
COPY entrypoint.sh /bin/
RUN chmod +x /bin/entrypoint.sh
USER fluent# fluent.conf
<match docker.swarm_reception-api**>
@type elasticsearch_dynamic
logstash_format true
logstash_prefix ${record['biz_client']}-reception-api
...
</match>
...다양한 클라이언트에서 데이터를 전송받으니 어떤 클라이언트인지 식별할 필요가 있습니다. Forwarder가 식별할 record를 하나 지정해서 보내주면 type을 elasticsearch_dynamic 로 선언해서 유동적으로 처리할 수 있습니다.
다중 match와 label등을 활용하여 데이터를 다시 분류 후 Elasticsearch로 전송하면 이를 바탕으로 드디어 Kibana에서 시각화가 가능해집니다.
📊 Elasticsearch와 Kibana
Elasticsearch와 Kibana는 직접 설치해서 사용해도 되지만 최근에는 여러 클라우드에서 쉽게 배포까지 자동으로 하는 환경을 만들어 줍니다. 더군다나 elastic.co에서는 사이트 내에서 클라우드로 자동 배포하고 매니지먼트까지 할 수 있는 기능들을 제공합니다.
배포 후 Kibana에 접속하여 Stack Management에서 Index Management를 확인해보면 index가 <client_name>-<docker_name>-<date>의 형식으로 생성되는 것을 확인할 수 있습니다.
이를 토대로 Kibana 인덱스 패턴을 만들면 EFK의 기본 과정은 끝이 납니다.
📃 끝으로
큰 Pipeline은 이렇게 구성되었습니다. 실제로는 더 다양하고 많은 Filter들과 설정들로 다소 복잡하게 구성됩니다. 그래도 제대로 가공된 데이터만 Elasticsearch로 전송할 수 있다면 Kibana에서 정말 편하게 다양한 정보를 확인할 수 있습니다.
그럼 여기까지 MSA, Docker Swarm Loggin을 위한 EFK 였습니다.